Conversation
Notices
-
Embed this notice
(mint@ryona.agency)'s status on Saturday, 10-Aug-2024 02:09:54 JST 
@feld Can you update Lazarus to include Oban 2.18 in supported range?
Screenshot_20240809_200603.png-
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:22:29 JST  feld
feld
@mint in your mix.exs go set Oban to override: true
There should be another example in the file to follow. That will allow it to work likes this. -
Embed this notice
(mint@ryona.agency)'s status on Saturday, 10-Aug-2024 02:24:07 JST
@feld Yeah, I instead made a copy of the repo and changed its mix.exs, then pointed pleroma's mix.exs to it. -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:24:32 JST
feld
@mint I take it you had another freeze/crash even with the latest changes in the branch? Well, let's see how long you can go on Oban 2.18. Nothing in that changelog looks relevant but hey, stranger things have happened 🤪 likes this. -
Embed this notice
Lina Inver?e (lina@eientei.org)'s status on Saturday, 10-Aug-2024 02:24:39 JST  Lina Inver?e
Lina Inver?e
@mint @feld оболонь 2.18 likes this. -
Embed this notice
(mint@ryona.agency)'s status on Saturday, 10-Aug-2024 02:25:17 JST
@feld Not yet, but I guess it's better to be prepared that to simply wait. Also updating containers to fresh Alpine version (with OTP 26 and Elixir 1.16). -
Embed this notice
(mint@ryona.agency)'s status on Saturday, 10-Aug-2024 02:27:03 JST
@feld Also is there a reason why there's been no mergeback that changes the develop version to 2.x.50? -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:32:38 JST
feld
@mint here's my current working theory:
Older Oban used the db triggers. It has very slight overhead, so they changed to the new method for more performance for the most demanding use cases.
If Postgres can't keep up with work and queries start timing out, Ecto/Postgrex (db driver and connection pooler) crashes and restarts. This would cascade up to Oban. And I think in some edge case it can cause Oban to come back online but not properly start the queue processing.
Now you stopped processing jobs. Super weird.
I have a lower resource test server I'm running now and following some relays -- feld@friedcheese.us. Feel free to flood me with follow requests from a giant bot network, I'll need more followers to stress this further 🤭 likes this. -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:35:02 JST
feld
@mint Got overlooked, open an issue so we don't forget to do it this weekend or I'll do it early next week likes this. -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:45:08 JST
feld
@i @mint It's still a passion project and I really love elixir so it's not going away. Lain wants to start cutting out complexity and unused functionality. There's low hanging fruit for performance improvements. e.g., I have plans to completely refactor and simplify the caching too with a new better approach (Nebulex). I hope to be running a Pleroma instance across multiple redundant tiny computers at home soon as proof of concept that we can scale horizontally and scale down just fine (database and media on another server, but good enough. Serious people can cluster / load balance that too)
It's also possible to run Pleroma with no frontend webserver. I've done this in another project to experiment. Works great! It can get its own certificate with LetsEncrypt and bind on real 80/443. -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 02:45:10 JST  :blank:
:blank:
@feld @mint too bad, i do wonder what pleroma would look like with a few full time devs at the helm, even if it's clean up the rest of the cruft -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:45:11 JST
feld
@i @mint It's true, but the dude made like the world's best modern job queue software so I can't be too mad at him for wanting to run a business and make a living.
Back in ~2018 I almost recruited him to work on Pleroma. We had funding for him, but he was too involved in contract work so it didn't go anywhere beyond initial discussion. I was ready to drive down to Chicago and bring him into our office too 😢 -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 02:45:12 JST
:blank:
@feld @mint makes sense, the pro and open split is annoying -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:45:13 JST
feld
@i @mint Lifeline will recover stuck / orphaned jobs but will not retry them if it was their "last attempt". Oban Pro has a better Lifeline plugin that can rescue these too based on custom rules.
I just forked theirs to detect if it was the last job and to reset it so it will be tried again. -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 02:45:14 JST
:blank:
@feld @mint why is it even a fork of Oban.Plugins.Lifeline? -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 02:51:28 JST
:blank:
@feld @mint good on you for keeping it going, definitely an appreciated effort, even if i'm not looking forward to rebasing all my changes on the recent pleroma develop changes any time soon
and lain is right, a leaner pleroma is a better pleroma for everyone involved
running a 15 node nebulex project right now, playing around with AP vaporware from time to time, it's still magical that libcluster can just gossips up a distributed KV cache with so little effort likes this. -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 02:51:33 JST
:blank:
@feld @mint we can still thank myfreecams for admin-fe, even if it's full of holes still likes this. -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 02:51:34 JST
feld
@i @mint Mind you we had full time devs on it from late 2017-2020, but the focus was almost exclusively on the backend. There were two frontend projects exploring the space as well. If I told you how much money was spent exploring the viability of the fediverse you'd never believe me. It has a lot of zeroes. Unfortunately the timing was just off and something else filled the void for my employer -
Embed this notice
narcolepsy and alcoholism :flag: (hj@shigusegubu.club)'s status on Saturday, 10-Aug-2024 03:01:14 JST  narcolepsy and alcoholism :flag:
narcolepsy and alcoholism :flag:
@feld @i @mint biggest problem with it is that it's barely maintained. We already have Admin Dashboard in PleromaFE, I'd rather keep improving that. -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 03:01:15 JST
feld
@i @mint Biggest problem with AdminFE is the difficulty of parsing the config because it's not already JSON or something more approachable. It's got some pretty gross hardcoded stuff in it. I personally want to replace it with one written in LiveView where it can directly work with the native config data structures no problem. If we could just get an initial PoC up that even controls one settings group the rest of the work is easy if not just a little tedious, but it could happen fast -
Embed this notice
Doughnut Lollipop 【記録係】:blobfoxgooglymlem: (tk@bbs.kawa-kun.com)'s status on Saturday, 10-Aug-2024 03:10:32 JST  Doughnut Lollipop 【記録係】:blobfoxgooglymlem:
Doughnut Lollipop 【記録係】:blobfoxgooglymlem:
@feld @i @mint Oh I love materials recovery facilities. :blobfoxgooglymlem: :blobfoxgooglytrash: -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 03:10:33 JST
feld
@i @mint I want us to have more MRFs, there are many floating out there that are useful.
Open an MR for that MRF and I'll fix the documented bug so we can merge it -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 03:10:34 JST
:blank:
@feld @mint a thousand cuts with very few additions that weren't added/invalidated by you later anyway, nothing upstream is/was interested in when brought up publicly/directly
would need to git clone and diff it out like the last few times i've done this when develop picks up pace again or a new feature i want releases
not sure people would be interested in nostr/outbox/relay scraping for instance
maybe software/similar mrf policies if they were cleaned up a bit?
https://256.lt/mrf/software_policy.ex this one still has a 8 month old bug/issue https://git.pleroma.social/pleroma/pleroma/-/issues/3211
https://256.lt/mrf/similar_policy.ex -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 03:10:35 JST
feld
@i @mint How much custom stuff do you have in your Pleroma? anything reasonable to upstream? I'd gladly help you rebase -
Embed this notice
narcolepsy and alcoholism :flag: (hj@shigusegubu.club)'s status on Saturday, 10-Aug-2024 03:14:13 JST
narcolepsy and alcoholism :flag:
@feld @i @mint >We cannot rely on PleromaFE to be the one true FE for Pleroma forever.
IMO we should but it's also planned to make a separate "admin dashboard only" build of FE to replace AdminFE without having to use PleromaFE or even have it installed.
>I really wish I had time to do more work in this area
Friendly reminder that NLNet grant is still up, there are some backend tasks in it. I work 80% at dayjob and on Wednesdays work on pleroma unless vacationing or depressed.Doughnut Lollipop 【記録係】:blobfoxgooglymlem: likes this. -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 03:14:14 JST
feld
@hj @i @mint We cannot rely on PleromaFE to be the one true FE for Pleroma forever. Soapbox isn't bad, and someone could take it over now that Gleason has mostly abandoned it for the fediverse. Phanpy is super cool. Something else could come out tomorrow, you could get hit by a bus, Lain could make an entirely new UI with his AI experiments, etc. Just can't predict the future.
I really wish I had time to do more work in this area but when I have time I gravitate towards problems I already know I can solve, and that's mostly backend work 😓 -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 03:16:58 JST
feld
@hj @i @mint I don't need the money I just need the time 😭😭😭
I really need to compile my list of small nits in the FE that need addressing and just pay you to knock them outnarcolepsy and alcoholism :flag: likes this. -
Embed this notice
narcolepsy and alcoholism :flag: (hj@shigusegubu.club)'s status on Saturday, 10-Aug-2024 03:19:33 JST
narcolepsy and alcoholism :flag:
@feld @i @mint I mean at least for me switching to 80% time at work gave me that much coveted free time I needed, nlnet money doesn't exactly cover the loss (basically dayjob=living grant=nice things) but I think it's better that way. -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 03:19:39 JST
:blank:
@feld @mint @hj same narcolepsy and alcoholism :flag: likes this. -
Embed this notice
narcolepsy and alcoholism :flag: (hj@shigusegubu.club)'s status on Saturday, 10-Aug-2024 03:20:27 JST
narcolepsy and alcoholism :flag:
@i @feld @mint I don't remember but it also might be a task in the grant. -
Embed this notice
(mint@ryona.agency)'s status on Saturday, 10-Aug-2024 03:27:04 JST
@NonPlayableClown @feld @i @hj At the very least Soapbox is still being updated since it's a default frontend for his MastoAPI->Nostr bridge. -
Embed this notice
NonPlayableClown (nonplayableclown@postnstuffds.lol)'s status on Saturday, 10-Aug-2024 03:27:05 JST  NonPlayableClown
NonPlayableClown
>...someone could take it over now that Gleason has mostly abandoned it for the fediverse.
Has that been confirmed?
I know he's working more on nostr, but not sure if it's a temporary job or not.
I think there's a lot of neat things in AdminFe and soapbox.
Hell if confirmed abandonware I wouldn't mind tweaking it in my spare time.
Though never worked much in elixir. -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 03:41:14 JST
:blank:
@mint @feld @NonPlayableClown @hj and https://github.com/BDX-town/Mangane is still maintained if the project ever explodes, though ditto being usable via other existing mobile masto-api clients is still a fundamental feature likes this. -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 03:41:19 JST
feld
@mint @NonPlayableClown @i @hj I just ran into some very serious usability bugs on mobile and when I asked him about it he was like "sorry, working on the Nostr stuff for now" so I just stopped using it
Not mad or anything, he can do whatever he wants likes this. -
Embed this notice
(mint@ryona.agency)'s status on Saturday, 10-Aug-2024 03:53:44 JST
@i @feld @NonPlayableClown @hj Readme still mentions how it's effective enough to run on a Raspberry Pi, meanwhile I'm struggling to run my instance on a somewhat decently specced machine from ~2013 with a SATA SSD. Regarding the jsonb schema, it sure feels wasteful; something like a separate table with likes/repeats/reacts that only references the post, type and user would've probably done the job just as well if not better. -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 03:53:45 JST
:blank:
@feld @NonPlayableClown @mint @hj just ignore it eventually exploding into a death spiral because your vps/sbc isn't running on a modern local nvme raid and a postgresql auto vacuum having to rewrite all the deep indexes from the constant delete spam cripples the instance for a few minutes then hours then days
it's fine, but just letting it crash loop doesn't leave a nice impression
lain is also right that people should know better and buy better specced servers, but we also lied to them for years about that not being the case -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 03:53:46 JST
feld
@i @NonPlayableClown @mint @hj I don't get why everyone's so mad about Pleroma'a schema. Where's the core issue? Are people just upset that there's jsonb instead of a billion columns? Is there a pervasive impression that those jsonb columns are slow? -
Embed this notice
:blank: (i@declin.eu)'s status on Saturday, 10-Aug-2024 03:53:47 JST
:blank:
@feld @NonPlayableClown @mint @hj glussy's schema is currently running into more issues than even pleroma's buckets of slop, if he doesn't figure it out in time, the project is basically dead on arrival
not faulting him for focusing on that for now -
Embed this notice
feld (feld@bikeshed.party)'s status on Saturday, 10-Aug-2024 04:41:55 JST
feld
@i @NonPlayableClown @mint @hj I think we could have a dedicated tombstones table so we can check for deleted there first, would probably help. Needs deeper investigation.
Some of the delete work cascading is annoying and I think we could do better there. I've already helped slow the pain by making deletes lower priority and with a narrower queue.
We have some triggers I am suspicious of and need to investigate deeper, but my memory is that these are totally Postgres FTS related. On that note I think even if you choose to use another search backend we still waste energy on the GIN/RUM indexing...
I think also there is an expensive operation for things like number of likes on a post. I wear I saw this count being embedded directly in the Object JSON and that's crazy to me if that's how it was implemented. So deletes require rewriting that row? Holy shit that's gonna bring pain and make your table a Swiss cheese mess over time.
Those post stats (likes, replies, quotes) should probably be in their own table, use FKs, etc. Counts could be cached, and a new activity or a delete should trigger a job to update the count async instead of blocking the commit
Stuff like that could help lower resource instances tremendously
Note I just fixed a bug where we appeared to have been updating the "unreachable_since" field for every instance on every successful activity published due to the test not matching reality. Imagine how many wasted queries that is😭😭😭 likes this. -
Embed this notice
Phantasm (phnt@annihilation.social)'s status on Wednesday, 14-Aug-2024 08:33:15 JST  Phantasm
Phantasm
@feld @mint I think that this theory is the very likely cause. I've updated FluffyTail to the same Oban version bump commit (dbf29cbae4) on Sunday and it finally broke under it's own weight. I've seen an increase in CPU iowait and disk backlog alerts that must be associated with the Oban v12 jobs migration, because nothing else has changed. I've also noticed a big increase in DB timeouts in the logs. Granted it's running on a garbage tier Frantech VPS with the DB being hosted on a slab with dmcache on the OS drive.
I'll leave the instance in its current failed state if you want more information.
My test instance (@phnt@oban.borked.technology) running on the cheapest OVH Cloud VPS is still working perfectly fine after a week and a half of 4x the traffic FluffyTail receives. likes this. -
Embed this notice
(mint@ryona.agency)'s status on Wednesday, 14-Aug-2024 08:39:52 JST
@phnt @feld Looks like the queue clogged up on salon again, this time managed to catch it just five minutes in. The theory might be true; worth noting that postgrex crashes used to cascade into crashing the whole pleroma (#2469), which stopped at around the same time freezes began. Some (but not all) of my instances were affected, had to make the script that curls API every 30 seconds and restarts it when receiving no response. -
Embed this notice
(mint@ryona.agency)'s status on Wednesday, 14-Aug-2024 08:41:43 JST
@phnt @feld Honestly crashes are preferable to that, since it can be mitigated with a trivial script. With freezes, you'd have to check the date of the last post in TWKN, and there's no guarantee that it was caused by the bug and not some external factors (e.g. broken VPN tunnel like in my setup). -
Embed this notice
(mint@ryona.agency)'s status on Wednesday, 14-Aug-2024 08:54:13 JST
@feld @phnt Yeah, it was, looks like that comment was a false lead all along. Don't know why I expected anything else. -
Embed this notice
feld (feld@bikeshed.party)'s status on Wednesday, 14-Aug-2024 08:54:14 JST
feld
@mint @phnt Okay, was this with the new Oban 2.18? -
Embed this notice
(mint@ryona.agency)'s status on Wednesday, 14-Aug-2024 09:11:22 JST
@feld @phnt Looks like similar symptoms have been reported for quite some time, including on versions that ran without issues here.
https://github.com/sorentwo/oban/issues/1037
https://github.com/sorentwo/oban/issues/1129
https://github.com/sorentwo/oban/issues/842
One recommended enabling TCP keepalives for postgres, I might try that.
https://github.com/sorentwo/oban/issues/493#issuecomment-1187001822 -
Embed this notice
feld (feld@bikeshed.party)'s status on Wednesday, 14-Aug-2024 18:02:15 JST
feld
@mint @phnt okay, my feld/debugging branch has a clean rollback of Oban to the 2.13.6 version. There is a migration that needs to run. The Oban Live Dashboard is not compatible if you were using it, so sorry about that. But let's see if this gives you stability again likes this. -
Embed this notice
(mint@ryona.agency)'s status on Thursday, 15-Aug-2024 02:31:57 JST
@feld @phnt Seems a bit radical for the solution, but okay. I do wonder, though, if moving Oban queue into separate database might help with I/O issues. Maybe even keep it in ramdisk. -
Embed this notice
feld (feld@bikeshed.party)'s status on Thursday, 15-Aug-2024 02:36:47 JST
feld
@mint @phnt the I/O should really be minimal which is what's baffling
it is possible to make Oban specifically use a dedicated SQLite database in newer releases (a dedicated postgres is possible too, of course)
but let's roll back to the Oban version you never had issues with and work from there. If it still has problems we know it's something else (Postgrex?) likes this. -
Embed this notice
(mint@ryona.agency)'s status on Thursday, 15-Aug-2024 02:38:41 JST
@feld @phnt Alright, when I'm done with maintenance on the other test server. -
Embed this notice
feld (feld@bikeshed.party)'s status on Thursday, 15-Aug-2024 02:41:02 JST
feld
@mint @phnt your patience is GREATLY appreciated and I'll grind through this with you until we have found the smoking gun likes this. -
Embed this notice
Phantasm (phnt@fluffytail.org)'s status on Thursday, 15-Aug-2024 02:41:35 JST  Phantasm
Phantasm
@mint @phnt @feld
> The theory might be true; worth noting that postgrex crashes used to cascade into crashing the whole pleroma
Similar thing happened to me, stalled federation and an hour later all connections on localhost were refused (Pleroma did not listen on it's port). When I used IEx to get access to it, IEx had no idea what Oban and Ecto were. likes this. -
Embed this notice
Phantasm (phnt@fluffytail.org)'s status on Thursday, 15-Aug-2024 03:14:30 JST
Phantasm
the I/O should really be minimal which is what's baffling
I've looked through the 2.17.0 release notes and sorentwo mentioned disabling the insert trigger functionality completely in config if "sub-second job execution isn't important." That should disable the insert trigger functionality that I suspected of the increased I/O and revert to polling only. After changing that with config :pleroma, Oban, insert_trigger: false the I/O did not change in any way. Still the same behavior. At this point I'm kinda lost at what the issue might be.
The documentation and release notes also mention different reasons for disabling the trigger:
https://github.com/sorentwo/oban/releases/tag/v2.17.0
https://hexdocs.pm/oban/v2-17.html#disable-insert-notifications-optionalI've also skimmed through Ecto and Postgrex GitHub issues and didn't find anything meaningful that mentioned increased I/O or Oban.
likes this. -
Embed this notice
feld (feld@bikeshed.party)'s status on Thursday, 15-Aug-2024 03:14:35 JST
feld
@phnt @phnt @mint the triggers were already removed by the Oban 2.17 v12 database migration, so that triggers setting would have no effect anyway likes this. -
Embed this notice
Phantasm (phnt@fluffytail.org)'s status on Thursday, 15-Aug-2024 03:47:15 JST
Phantasm
@feld @phnt @mint Updated instance to the newest commit on feld/debugging and downgraded Oban. There's no point in me trying to find it on my own as I have no other clues.
Will report back if it stalls again. likes this. -
Embed this notice
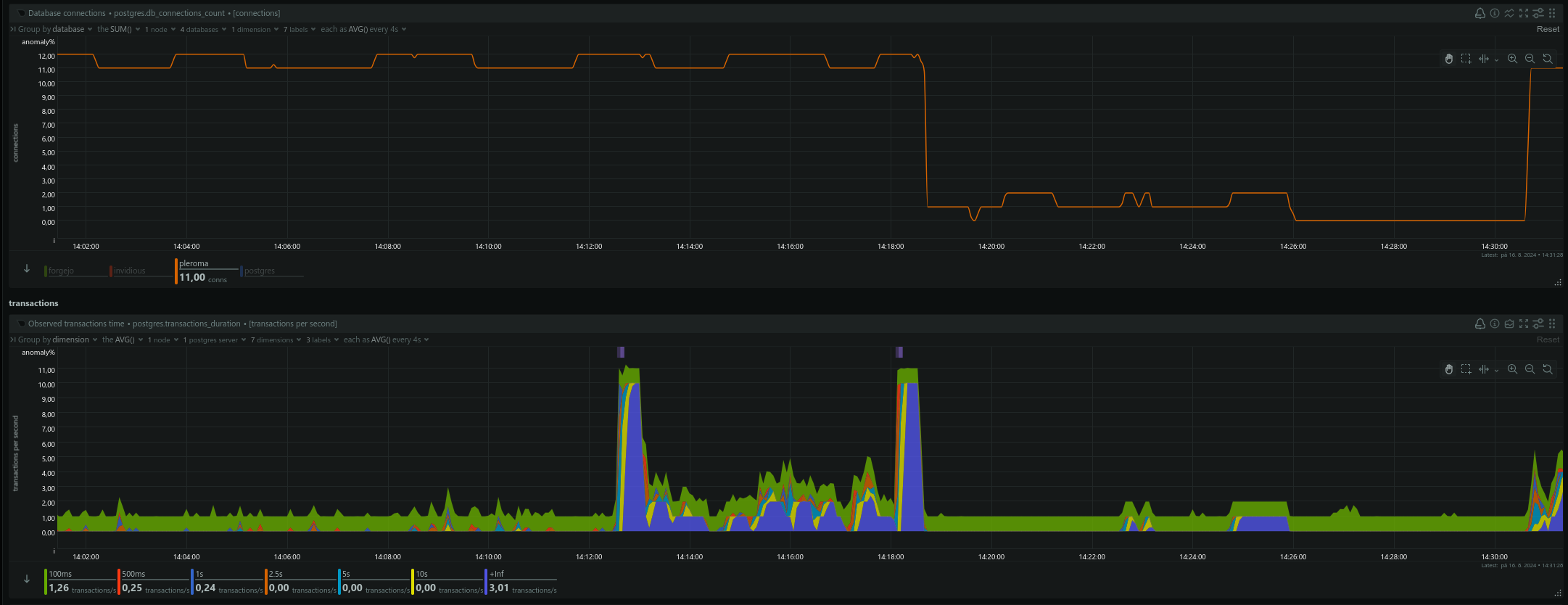
Phantasm (phnt@fluffytail.org)'s status on Friday, 16-Aug-2024 23:24:15 JST
Phantasm
@feld @mint @phnt Pleroma crashed again ~1 minute after I made a post. federator_incoming queue had 0 available jobs, and few retryable. federator_outgoing had 7 failed jobs and zero available/executing.
Same thing just like last time. Out of nowhere a jump in disk backlog for a minute, disk busytime and Pleroma DB locks. Had almost zero DB timeouts before that.
Before the crash a lot of (DBConnection.ConnectionError) connection not available and request was dropped from queue after <some number>ms. This means requests are coming in and your connection pool cannot serve them fast enough. showed up in logs. Pleroma used at maximum 12 DB connections. Number of connections or pool size are from the default config, only :pleroma :connections_pool, connect_timeout was increased to 10s from default 5s. :pleroma, Pleroma.Repo, timeout was also increased to 30s.
The Netdata screenshots are from the same time. Ignore the time difference. Server is UTC-4 (US ET) and Netdata is UTC+2 (CEST).
pleroma-crash_20240816.txt
postgres-crash_20240816.txt likes this. -
Embed this notice
feld (feld@bikeshed.party)'s status on Friday, 16-Aug-2024 23:24:16 JST
feld
@phnt @phnt @mint I'm a little confused about why there are duplicate/retry jobs firing so quickly as there are some things in the logs that shouldn't be happening successively like that. They may not be the root cause but they're definitely adding to the pressure and we can address it likes this.
-
Embed this notice
{kind=link}
{kind=link}
{kind=link}