Untitled attachment
{kind=link}
https://upload.fluffytail.org/media/b3b3dbe728d025af3124231a1d4efb0f23bfa5c6a81e7ae4c69ee4a7e0fd9f60.png?name=image.png
@feld @mint @phnt Pleroma crashed again ~1 minute after I made a post. federator_incoming queue had 0 available jobs, and few retryable. federator_outgoing had 7 failed jobs and zero available/executing.
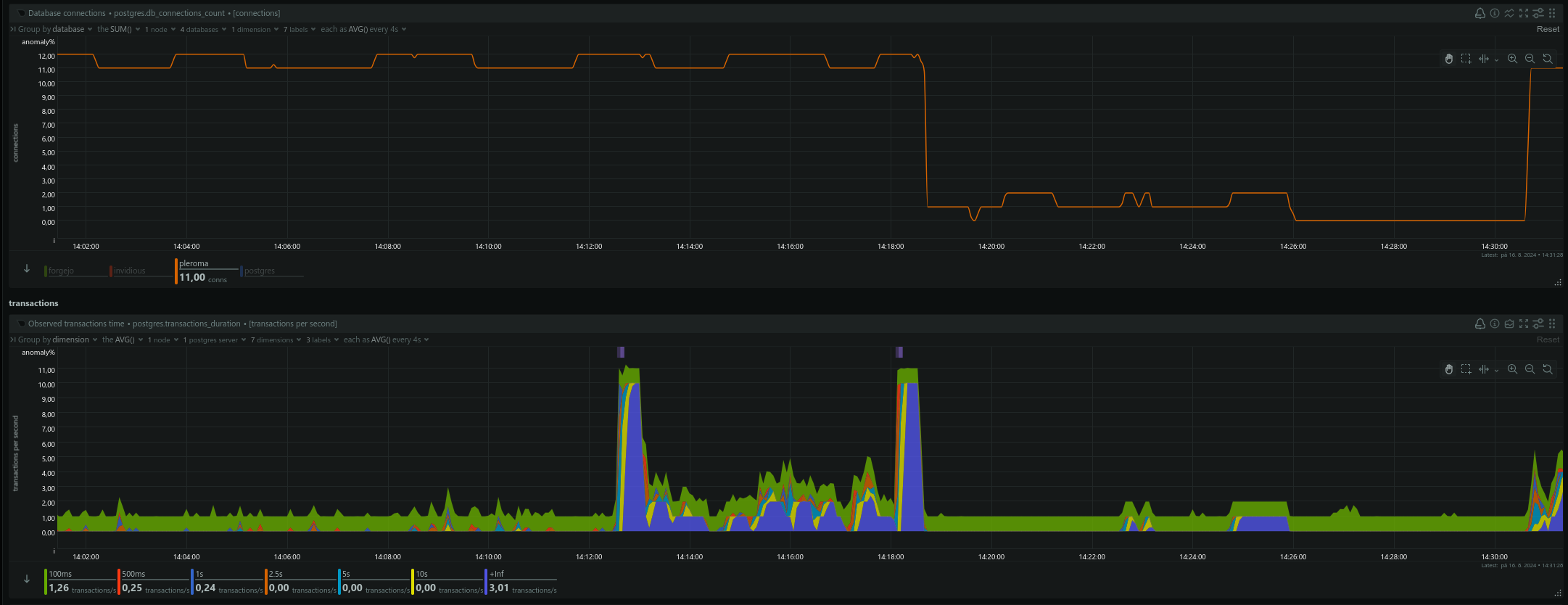
Same thing just like last time. Out of nowhere a jump in disk backlog for a minute, disk busytime and Pleroma DB locks. Had almost zero DB timeouts before that.
Before the crash a lot of (DBConnection.ConnectionError) connection not available and request was dropped from queue after <some number>ms. This means requests are coming in and your connection pool cannot serve them fast enough. showed up in logs. Pleroma used at maximum 12 DB connections. Number of connections or pool size are from the default config, only :pleroma :connections_pool, connect_timeout was increased to 10s from default 5s. :pleroma, Pleroma.Repo, timeout was also increased to 30s.
The Netdata screenshots are from the same time. Ignore the time difference. Server is UTC-4 (US ET) and Netdata is UTC+2 (CEST).
GNU social JP is a social network, courtesy of GNU social JP管理人. It runs on GNU social, version 2.0.2-dev, available under the GNU Affero General Public License.
![]() All GNU social JP content and data are available under the Creative Commons Attribution 3.0 license.
All GNU social JP content and data are available under the Creative Commons Attribution 3.0 license.
{kind=link}