Notices where this attachment appears
-
Embed this notice
@phnt you're awakening my graphomania right now. my inner @p. I'm loving it
> I'm a bit surprised cawfee didn't fall over often because of it.
not everything was on the slab, I deliberately keep about 5-10 of the last 1GB files from both objects and activities on the main drive at all times. there were noticeable slowdowns when querying older data, and of course occasional errors were always there, but in the grand scheme of things shit just ran
> Just out of curiosity, did Postgres crash when it ran out of disk space,
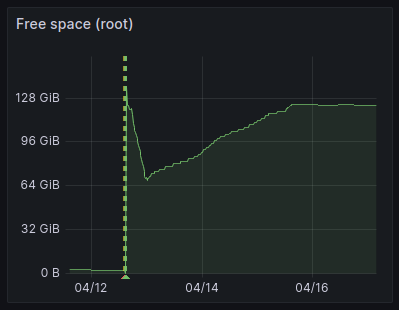
yes, there was about 2GB free and that quickly filled up. even after moving most of the DB to the slab and running the prune again, it quickly ate a lot of space and then rebounded (fig. 1)
>A crash would make it not reclaim the disk space lost by the failed vacuum full on crash recovery. You can't get rid of those files without doing a pg_dump, dropping the full database(s) and restoring it from scratch.
yeah, when this happened, I just restored all the DB files from a backup I made at the start of the maintenance. they're not retained, at least from this failure. but it might have happened earlier
> You can't get rid of those files without doing a pg_dump, dropping the full database(s) and restoring it from scratch.
the last time I used pg_restore was in 2021 and it took three days (https://info.cawfee.club/soti-2021-09.html)
> I don't know if cancelling the query is a good option, since it has the potential to cause the infamous pruned DB meme.
yeah, I don't think killing the query would be wise - but what to do? at the moment, what seems like the best approach to me is just `systemctl restart postgres-12`, which would cancel the query without wrecking the WAL and other things. am I mistaken?
funnily enough the mix process is dead but the query keeps running. I expected it to finish over the maintenance weekend and forgot to run it in tmux, and when it was time to go to work on Monday, I tried to disown the process and reattach it to tmux, which failed (multithreaded process or something, maybe I just fucked it up) but the query keeps running, as pg_stat_activity and disk graphs show. I'm not entirely certain about what's actually happening, as `SELECT count(*) FROM public.activities;` keeps giving me 105514556, same as when I first tried running it hours ago
{kind=link}