I think this is very interesting but really very _basic_ research on the capabilities of LLMs at reasoning problems. Any random PhD should be able to move from a static benchmark of math problems to a distribution of similar problems. That's exactly what this paper does, and discovers:
1. All current models do worse at GSM8K-like problems than they do on GSM8K itself, and there is wide variation in success for different samples.
2. #LLM performance varies if you change the names. It changes even more if you change the numbers. Change both, and you get even more variation.
3. Adding more clauses to the word problems makes the models perform worse.
4. Adding irrelevant information to the word problems makes the models perform worse.
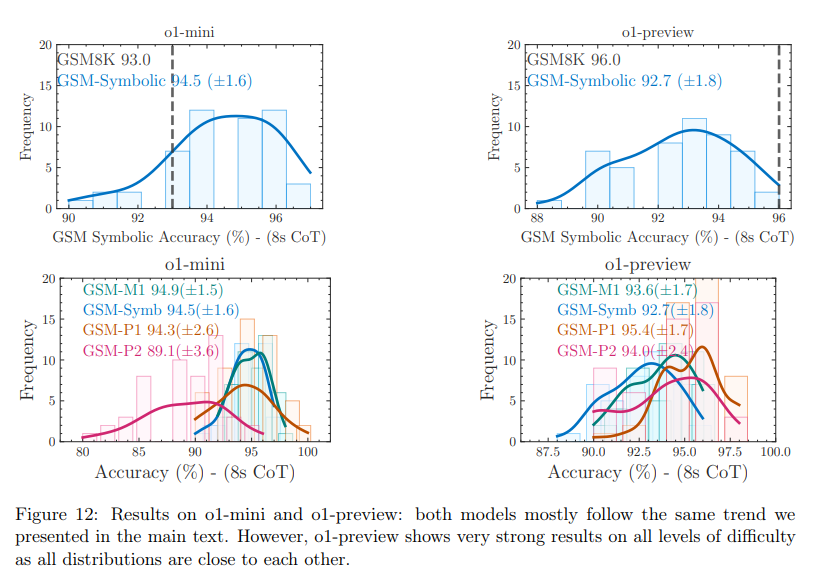
5. Even the latest o1-minit and o1-preview models, while they score highly, show the same sort of variability.
I think this is the bare minimum we should be expecting of "AI is showing reasoning behavior" claims: demonstrate on a distribution of novel problems instead of a fixed benchmark, and show the distribution instead of the best results.
It's not that humans don't share similar biases -- plenty of middle-school students are tripped up by irrelevant data too -- but I think results like this show we are very far off from any sort of expert-level LLMs. If they show wide distribution of behavior on tasks that are easy to measure, it's quite likely the same is true on tasks that are harder to measure.
https://arxiv.org/abs/2410.05229
{kind=link}