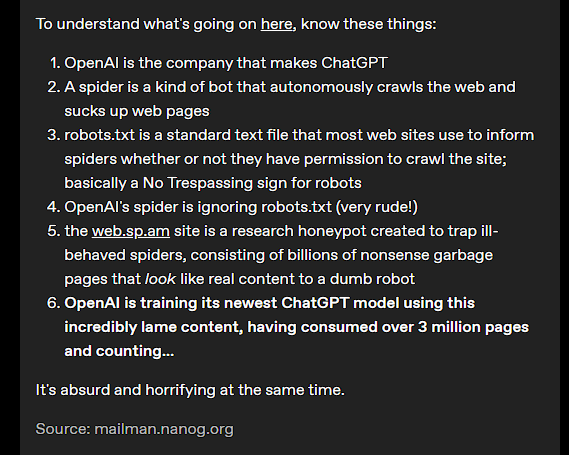
To understand what's going on here, know these things: OpenAI is the company that makes ChatGPT A spider is a kind of bot that autonomously crawls the web and sucks up web pages robots.txt is a standard text file that most web sites use to inform spiders whether or not they have permission to crawl the site; basically a No Trespassing sign for robots OpenAI's spider is ignoring robots.txt (very rude!) the web.sp.am site is a research honeypot created to trap ill-behaved spiders, consisting of billions of nonsense garbage pages that look like real content to a dumb robot OpenAI is training its newest ChatGPT model using this incredibly lame content, having consumed over 3 million pages and counting... It's absurd and horrifying at the same time.
{kind=link}
https://static.toot.community/media_attachments/files/112/268/194/879/706/394/original/b2d500df292cc186.png